

One of the benefits of a progressive web app is that we don’t break the paradigm of history or the expectation of our users. Links exist right in the top bar as they always have, easy to copy, paste, and place any where you may so please.
Alas, what may simply be a blue link in an email doesn’t have the same luster on the social networks of your choice with progressive web apps. Ever pasted one to see what happens? You will probably not be overcome with joy, seeing the default metadata that’s set in your shell.
The situation is pretty clear: our pwa link may work entirely fine when visited, but the default information is probably what we don’t want when it comes to specific things a user might share. What’s a web developer to do?
I’ve got this hammer, errr, JavaScript
A betting person might say “Well bots are totally super smart now, I hear machine learning is all the rage, surely the bot can run my JavaScript.”
Alas, in my testing I found that was not the case. I tested a variety. Facebook, Slack, Twitter, LinkedIn, Google+. Nope, not a single one would read the dynamically set tags. A cursory glance over similar questions on Stack Overflow also shows people with similar problems and results.
Time to put that hammer down. What else can we do?
When you’ve got a shell, everything is data
If we can’t run JavaScript to inject metadata to appease the bots, we need some rewrite magic. We need some static pages. Well, sort of, but I’ll get to that.
“But Justin, I don’t want to have two sets of content I have to maintain, that would be a massive pain in my backside.”
Alas, that would indeed be a pain random web developer. No one wants to do that. If only we had separated concerns, like if our data wasn’t tied to our design or something like that.
Humm…sounds a lot like what we have with our progressive web app shell doesn’t it?
What if we had a different, statically generated shell that simply used our data or endpoint to fill that shell for the social linkbot? Then we would wouldn’t need to duplicate our data. We could even do something better: we could make it the most barebones set of data ever, as we only need it for them.
We could make the linkbot experience faster for our end user.
Sounds like a reasonable plan. Let’s build that.
Let’s spork a repo to 11
In my case, I built our corporate progressive web app running on Google App Engine using the H2 Push approach (see http2push-gae). This wasn’t a stretch (our site/app has run on GAE for years), but I really like what the Google Chrome team have come up with. It’s a clean, fast, effective way to get a lot of perf without much overhead.
We’re going to fork it make it work with our data and our hungry linkbots.
First thing we have to do is come up with a list of bots. This is the list we settled on, purely based on Google Analytics data we had (in no particular order):
Since we’re using the Python variety, what we really need to do is simply test our user agent (gasp!) to see if we’re a bot:
Sidebar: Google+ uses the user agent from the user who is about to share your link and appends the url you see escaped in that list. Hence, the escaped url, which is what I found to be the most reasonable way to test for someone sharing on Google+.
Now it’s simply a matter of taking the target the user is looking at and translating it into data to feed into a static template.
We just need to know which data to load. In our case, we know this by looking at self.request.path. We house our data under our web root in a super secret folder we call data (I know, unguessable isn’t it?). Since our data is generated via Hugo, the Go-based static site generate, paths within the progressive web app actually house the same routes, just with data pre-appended (as we’re loading JSON into our app shell). We can simply build a path like:
Now that we know which JSON to load, we open the file, read it it, parse the JSON and pass it to our webapp2 template:
Sweet simplicity. In testing it looks like this on the App Engine console:
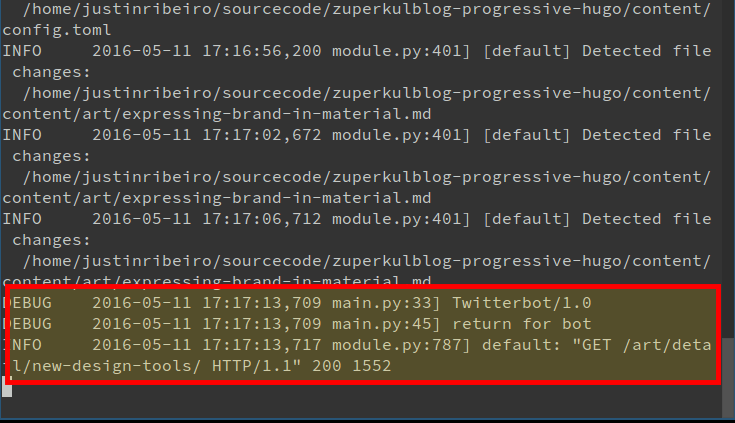
We’re on the right track. Now let’s give that bot some data so our PWA can be in further awesome.
Just the facts, server
Linkbots want really one thing: metadata. Some want their specific thing (ala Facebook and Twitter), others will use just about whatever it can find (Slackbot, Google+, LinkedIn). Why this matters is because you don’t have to serve much of anything. Just serve the head of your document with the proper tags.
We settled on this for the corp site (a more slim example can be found in my zuperkulblog-progressive-hugo repo):
Yeah, that’s it. There is no body, no styles, nada. The bots have all they need in those tags and the beauty of this is, the overhead is minimal.
Testing our results
Testing in this case either can happen through an ngrok tunnel to the local dev server or you can always push versioned revisions to App Engine before switching over to production.
Testing the links themselves is fairly simple. Facebook has their share debugger and Twitter has their card validator. These are valuable tools on our quest for making sure our metadata shell and matching work.
To test this working. I used my forked and hacked up clone of Rob Dobson’s zuperkulblog-progressive, zuperkulblog-progressive-hugo.
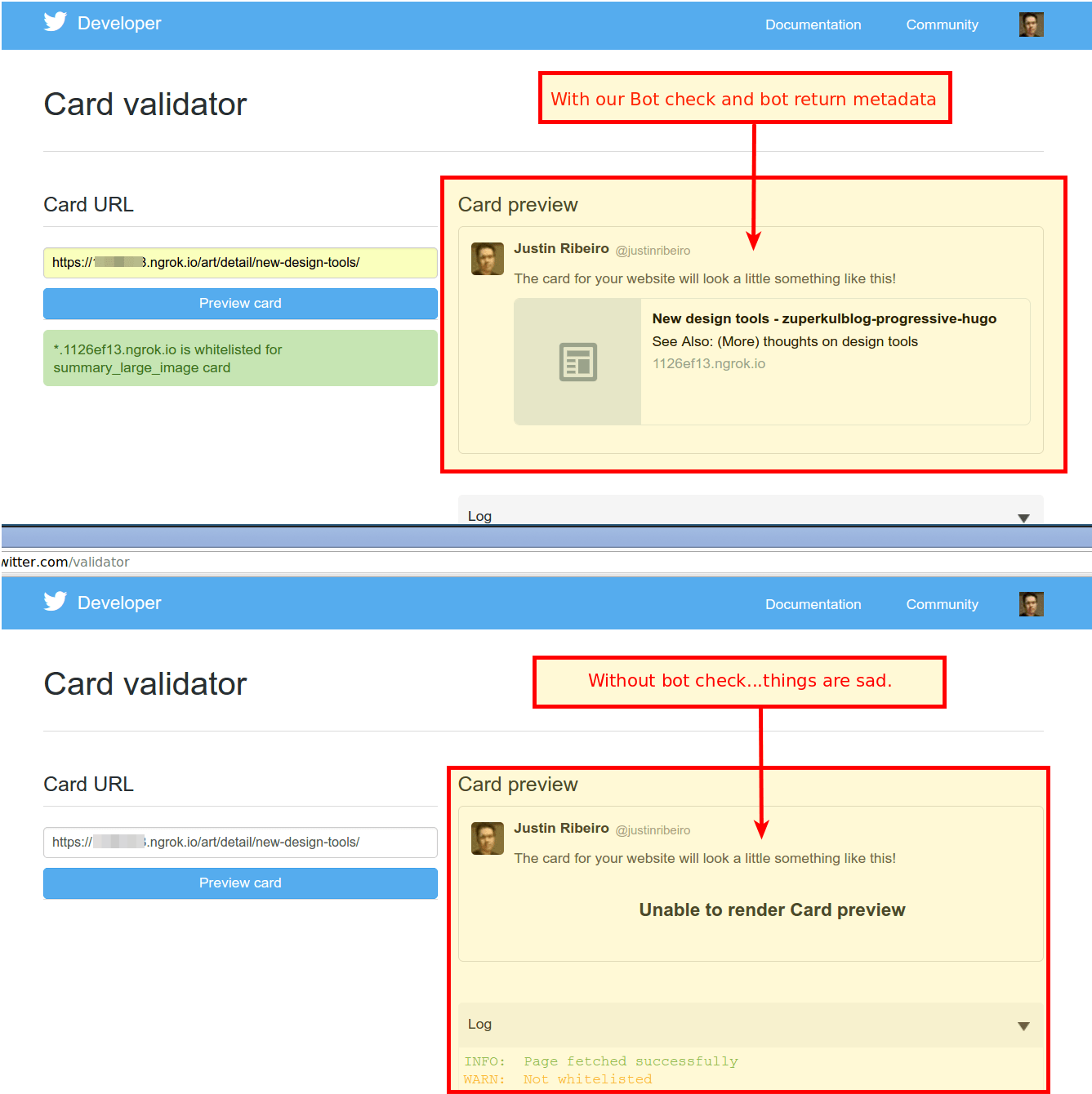
As you can see Twitter now very much thinks our progressive web app is much happier as opposed to the non-bot version.
The rest of the social networks don’t seem to have a means to test, but we didn’t have any issue just dropping links in random share boxes and testing the metadata pull. One issue to keep in mind (which is why ngrok can be useful, as it rotates domain names in use when restarted) is metadata caching (which most of the services do in some form).
You’re missing a bot and it has me worried
The careful reader will note that I’ve talked about linkbots, the one’s that share things on the places we all like to have social interactions. There is a very important, very large, and very unignorable bot that’s absent from this list: Googlebot.
Googlebot is in it’s own sphere. One, it’ll run JavaScript. Two, it’ll read dynamic structured data you inject. Three, you shouldn’t make pages specific to Googlebot like I’ve done for these other bots (you can in certain cases, ala AMP, but that is a topic for another progressive web app day).
The short answer is that Googlebot will read and index our progressive web app just fine if we take a couple of things into account. In my corporate case, our site has specific pages of static text, blog entries, random labs and code. These show up in a standard sitemap.xml file at the root, with no special instructions. The only pieces of magic code we’ve used is to swap page titles and meta descriptions with some simple JavaScript on route changes.
Skeptical this gets indexed? Yeah, we were to. That’s why we tested it:
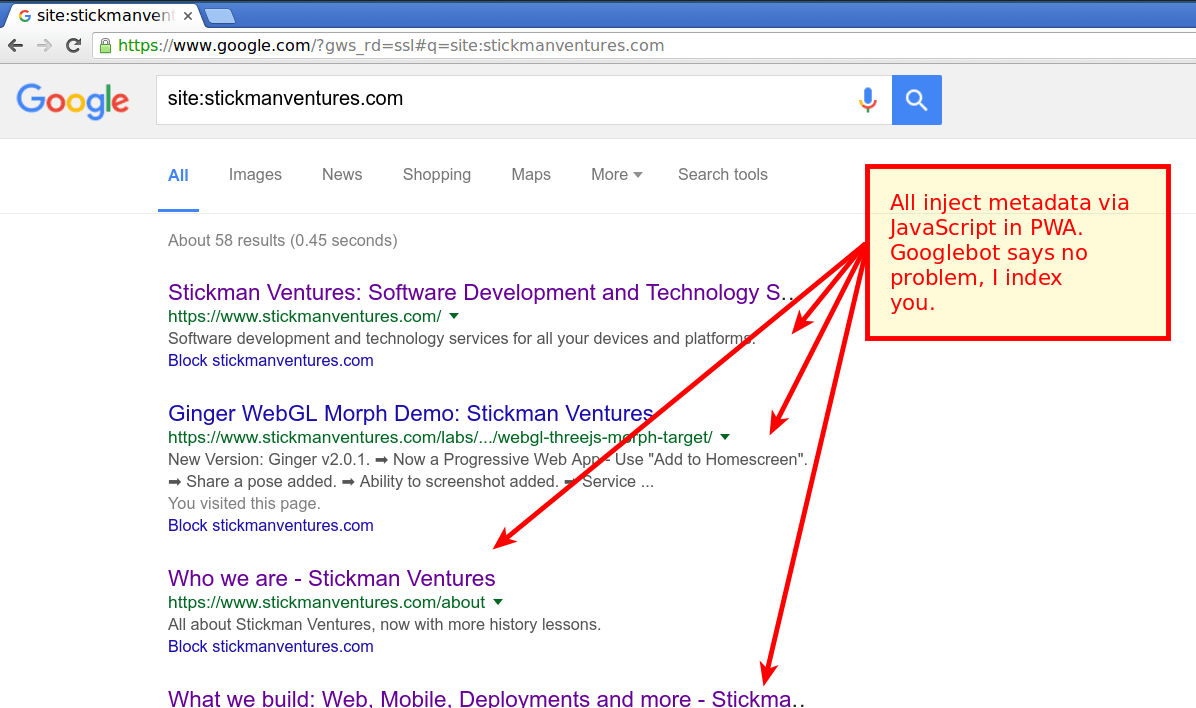
Tada! Magic! Googlebot happily sees our data changes and if we search for words in our injected pages, we can see Googlebot happily indexing our site. On our tiny production corporate page to boot.
Risk is fun.
Long and Short: Do you need special pages for Googlebot when it comes to progressive web apps? In this first small test, Google seems to have no problem indexing. When in doubt, follow Google’s WebMaster guidelines, but I’m continuing to test to see what PWAs need when it comes to seach.
Solid results, more to come
One of the hallmarks of progressive web apps are that they should be linkable (it’s what makes the web awesome right?). The thing about linkable is that means that they should also play nice with where people paste links, including in our social networks. Social network use bots to grab a better idea of what that page is about to inform the user, so our progressive web apps should probably take this into account.
This example uses App Engine, but you could no doubt apply it to your technology of choice. Want to test it out? I’ve dropped an update to my ongoing hugo + progressive mashup, zuperkulblog-progressive-hugo.
In our next installment, I’ll be talking more about the nature of the word “progressive” and why you should put down the pitchforks and torches.